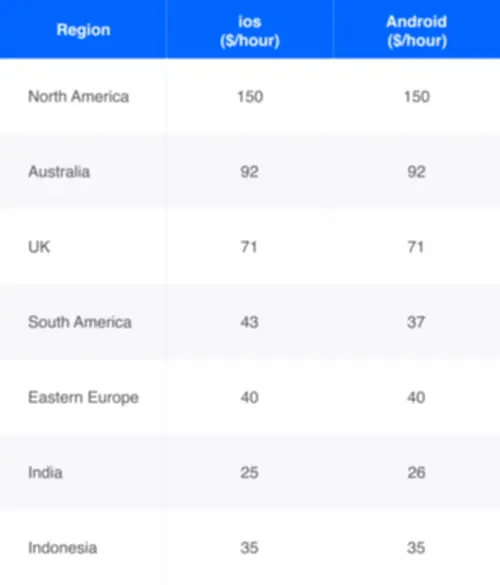
To practice the RNN, we want sequences of fastened length (seq_length) and the character following each sequence as the label. We outline the enter text and establish Mobile app development distinctive characters in the textual content, which we’ll encode for our model. Master MS Excel for information analysis with key formulation, functions, and LookUp instruments on this comprehensive course. Ever marvel how chatbots perceive your questions or how apps like Siri and voice search can decipher your spoken requests?
Real-life Functions Of Deep Studying In Healthcare
This consistency ensures that the mannequin can generalize across totally different parts of the data. The primary forms of rnn applications recurrent neural networks embrace one-to-one, one-to-many, many-to-one and many-to-many architectures. Recurrent neural networks suffer from an issue known as vanishing gradient, which can be a typical drawback for other neural network algorithms. The vanishing gradient problem is the end result of an algorithm referred to as backpropagation that allows neural networks to optimize the training process.
- Each unit accommodates an inner hidden state, which acts as memory by retaining info from earlier time steps, thus permitting the community to retailer past data.
- Bidirectional RNN permits the mannequin to course of a token each in the context of what got here earlier than it and what got here after it.
- The output of an RNN may be tough to interpret, particularly when coping with complicated inputs corresponding to natural language or audio.
- Each greater degree RNN thus studies a compressed representation of the data in the RNN beneath.
- The looping construction permits the network to store previous information in the hidden state and function on sequences.
Information With Irregular Frequencies And Missing Timestamps
This process of adding some new information could be accomplished via the enter gate. With the present enter at x(t), the input gate analyzes the essential info — John performs soccer, and the reality that he was the captain of his school staff is important. RNNs are inherently sequential, which makes it difficult to parallelize the computation.

Step 2: Define The Input Text And Prepare Character Set
The big-O here is irrelevant for the architectures since it’s all in the configuration & implementation of the mannequin; i.e. there isn’t any relevant asymptote to compare. In Ye Olden days (the 90’s) we used to approximate non-linear fashions using splines or seperate slopes fashions – match by hand. They were still linear, but with the proper selection of splines you would approximate a non-linear mannequin to no matter diploma of accuracy you needed. “only” is doing lots work right here as a outcome of that non-linearity is sufficient to vastly increase the panorama of features that an NN can approximate.

Backpropagation Through Time And Recurrent Neural Networks
LSTM is a popular RNN structure, which was introduced by Sepp Hochreiter and Juergen Schmidhuber as an answer to the vanishing gradient problem. That is, if the previous state that’s influencing the present prediction isn’t within the latest past, the RNN model may not have the ability to precisely predict the present state. Like many neural community fashions, RNNs usually act as black bins, making it troublesome to interpret their selections or perceive how they are modeling the sequence information. Recurrent Neural Networks (RNNs) operate by incorporating a loop within their structure that permits them to retain information across time steps.
This is beneficial in eventualities the place a single data point can result in a series of selections or outputs over time. A traditional example is picture captioning, where a single enter picture generates a sequence of words as a caption. The RNN’s capacity to take care of a hidden state permits it to be taught dependencies and relationships in sequential information, making it powerful for tasks where context and order matter.
The word you expect will depend upon the previous couple of words in context. RNNs may be computationally expensive to coach, especially when coping with lengthy sequences. This is as a outcome of the community has to course of each enter in sequence, which may be slow.
Modelling time-dependent and sequential knowledge issues, like textual content technology, machine translation, and inventory market prediction, is possible with recurrent neural networks. Nevertheless, you’ll uncover that the gradient problem makes RNN troublesome to train. RNNs share similarities in enter and output constructions with different deep studying architectures but differ significantly in how info flows from input to output. Unlike traditional deep neural networks, where every dense layer has distinct weight matrices, RNNs use shared weights across time steps, allowing them to remember data over sequences. A truncated backpropagation by way of time neural network is an RNN in which the number of time steps in the input sequence is restricted by a truncation of the input sequence. A recurrent neural network is a type of artificial neural network commonly used in speech recognition and natural language processing.
This allows calculating the error for every time step, which allows updating the weights. Note that BPTT can be computationally expensive when you’ve a high variety of time steps. This permits picture captioning or music technology capabilities, because it makes use of a single input (like a keyword) to generate multiple outputs (like a sentence). However, since RNN works on sequential data here we use an updated backpropagation which is called backpropagation through time. In sentiment evaluation, the model receives a sequence of words (like a sentence) and produces a single output, which is the sentiment of the sentence (positive, negative, or neutral). Standard RNNs that use a gradient-based learning technique degrade as they grow greater and extra complicated.
So, RNNs for remembering sequences and CNNs for recognizing patterns in house. Recurrent Neural Networks (RNNs) are deep studying fashions that might be utilized for time sequence analysis, with recurrent connections that allow them to retain info from previous time steps. Popular variants embody Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU), which can be taught long-term dependencies.
The deviations underscore that the mannequin falls short in capturing the true consumption patterns accurately. To assess the efficiency of the skilled RNN model, you can use evaluation metrics similar to Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and Mean Absolute Percentage Error (MAPE). These metrics quantify the accuracy of the predictions in comparability with the actual values and supply priceless insights into the mannequin’s effectiveness. Gated Recurrent Unit (GRU), a simplified model of LSTM with two gates (reset and update), maintains effectivity and efficiency just like LSTM, making it extensively utilized in time sequence duties. All RNN are in the form of a sequence of repeating modules of a neural network.
A. RNNs are neural networks that course of sequential information, like textual content or time collection. They use internal memory to remember previous data, making them appropriate for language translation and speech recognition duties. In the middle layer h, a number of hidden layers could be discovered, each with its activation capabilities, weights, and biases. You can utilize a recurrent neural network if the various parameters of various hidden layers usually are not impacted by the previous layer, i.e., if There is no reminiscence within the neural network. RNN unfolding, or “unrolling,” is the method of increasing the recurrent construction over time steps.
This looping mechanism enables RNNs to remember previous info and use it to affect the processing of present inputs. This is like having a memory that captures details about what has been calculated up to now, making RNNs notably fitted to duties where the context or the sequence is crucial for making predictions or decisions. To perceive RNNs correctly, you’ll need a working data of “normal” feed-forward neural networks and sequential knowledge. RNNs leverage the backpropagation by way of time (BPTT) algorithm where calculations rely upon previous steps. However, if the value of gradient is too small in a step throughout backpropagation, the worth can be even smaller in the next step. This causes gradients to lower exponentially to a degree where the mannequin stops learning.
Transform Your Business With AI Software Development Solutions https://www.globalcloudteam.com/ — be successful, be the first!